Internet Educational Series #4: DNS (Domain Name System)
But… you told us computers use numbers to identify themselves, how can I connect to medium.com then?

When we want to send data through the internet, we must know the IP address of the destination device to send an IP datagram.
However, IP addresses (IPv4) are something like 192.168.0.1, or 172.16.255.255, and for humans those numbers are hard to remember. We tend to remember easier names than numbers, and that’s why the DNS was invented.
DNS stands for Domain Name System, and it links names with IP addresses in the Internet.
How does it work?
Now, the question is how to implement the DNS. How can our computer know which IP corresponds to each name?
The first time the DNS was implemented, the Internet was so small that simply having a local file of translations in each computer was enough.
In Unix-like systems, such file is the /etc/hosts, and it contains lines of text with name translations in the form “address”, “long name” and “short name”.
If we take a look at our file:
$ cat /etc/hosts
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhostWe can see our localhost and broadcast addresses.
However, the Internet continued evolving, and it became so huge so quickly that another system had to be thought.
Take a look at the figure below, note that it is displayed logarithmically
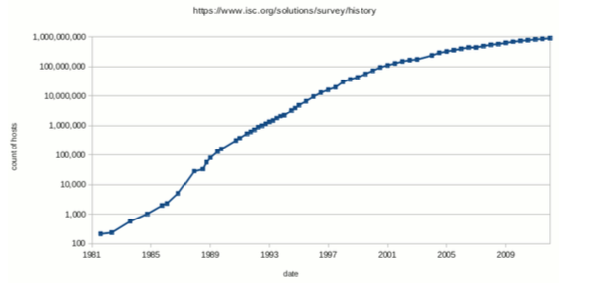
The first proposed solution was to store all the translations in a server and only use the “hosts” file for specific local translations, that’s why we can only see my localhost and broadcast address.
The file and the centralized server were maintained by an organization called InterNIC.
Obviously they realized that this wasn’t either a good idea, and that a more decentralized approach should be clearly taken, as more and more users joined the network.
Decentralized Solution
To provide efficient name translations and delegation is best to use a distributed database (multiple servers) with a variable depth hierarchical name space.
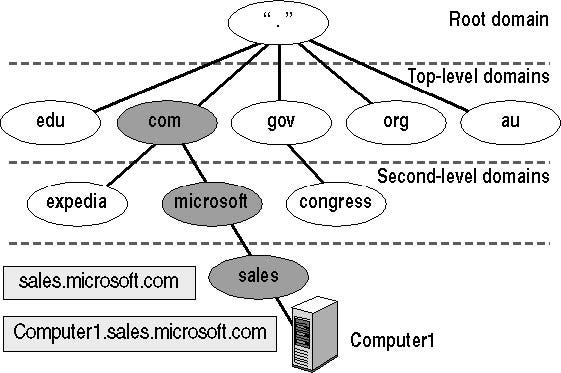
This literally means that the names can have different lengths and that they are ordered in a hierarchy.
This hierarchy allows name delegation and name uniqueness. With this solution we can have several devices with the same short name or unqualified name (such as www) but each device can have a different long name or Fully Qualified Domain Name (FQDN), such as sales.microsoft.com.
Domains
The name space of the DNS tree is divided into domains. A domain includes all the names ending with that domain suffix. For example, the domain .com includes all the names ending with .com, like medium.com, github.com, and a long long list of names.
Domains are classified according to their level or depth inside the DNS hierarchy.
First level domains are managed by governmental organizations, countries or special agencies related with Internet.
Second level domains are managed by private entities. An example of second level domain is medium.com.
Additionally, there is a top level or root domain. This domain is the dot domain: “.”, and it is managed by InterNIC.
Take a look at the following picture
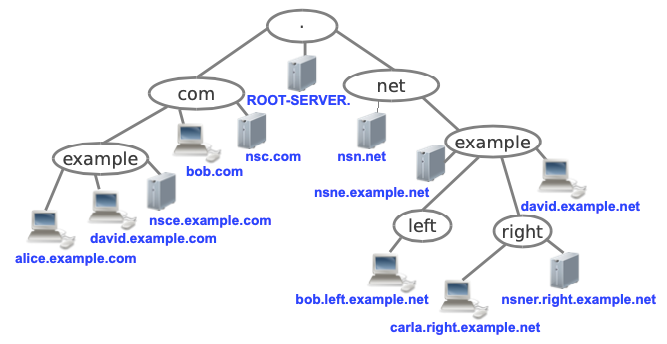
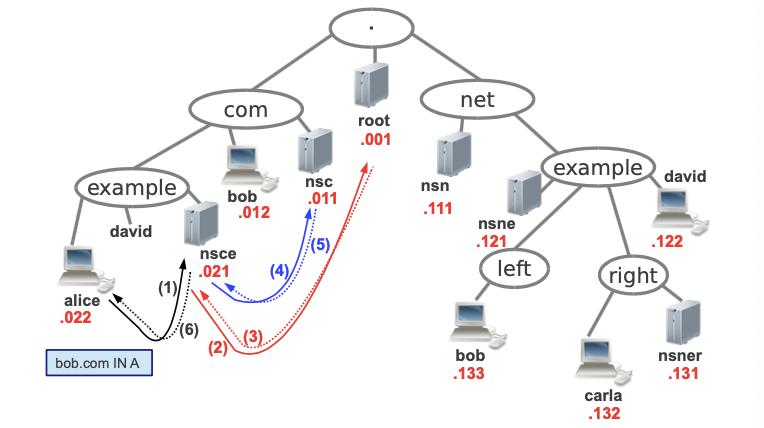
If we count the number of domains in this picture we can see there are 7: “dot”, .com, example.com, .net, example.net, left.example.net, right.example.net.
Each domain has one or more network devices connected to it. We will refer to this network devices as the “tree leaves”.
We can see how the domain .com has 2 leaves: bob.com and nsc.com.
Zones
When we want to delegate petitions of name translations, the DNS tree is administratively divided into zones. A zone is an administration point, that contains a configuration file containing a set of translations that is managed by a master or primary name server.
Each zone can have multiple servers, and a server can serve multiple zones, but to make it easier to understand, we are going to assume that each zone is implemented with just one server and that each server just serves that zone.
Take a look at the possible zones that we could have with the previous tree:
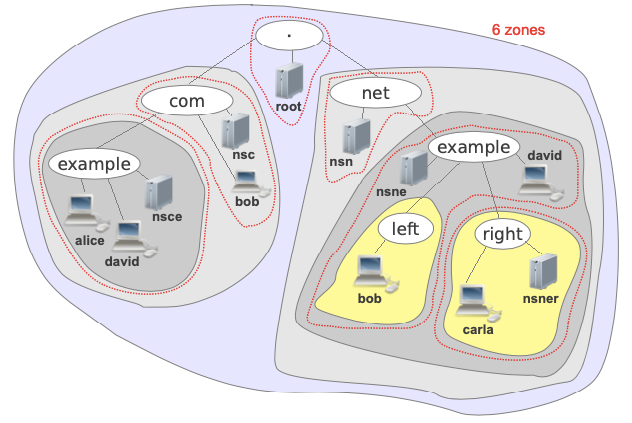
As you can see we’ve separated the 7 domains into 6 zones. The server root is in charge of the zone dot (“.”), and it has translations of all the names except the ones that it has delegated. In our case, the root server delegates .com and .net, so in case there are no more devices it will just know the translation of nsc and nsn to delegate all the names ending with .com and .net.
The domain .com is managed by nsc and the .net by nsn.
The server nsc manages all the names ending with .com except those ending with example.com.
The domain example.com has been delegated to a server called nsce, thus the translation of bob.com is stored in nsc but the translation of alice.example.com is stored in nsce.
In the nsn branch we could see similar zones except the left one, which we chose to make a single zone for either example.net and left.example.net. Why did we choose to do that? Because there is only one device that hangs from the left branch, and it can be already managed by nsne, there is no need to add another server there to store the information of bob.left.example.com. Of course we could have divided that into two different zones, one for example.net and another one for left.example.net, but they both would have been served by nsne.
The network addressing is done orthogonally respect to the hierarchy of the domain.
In our example, we have a single IP network 10.0.0.0/24, which is addressed as follows:
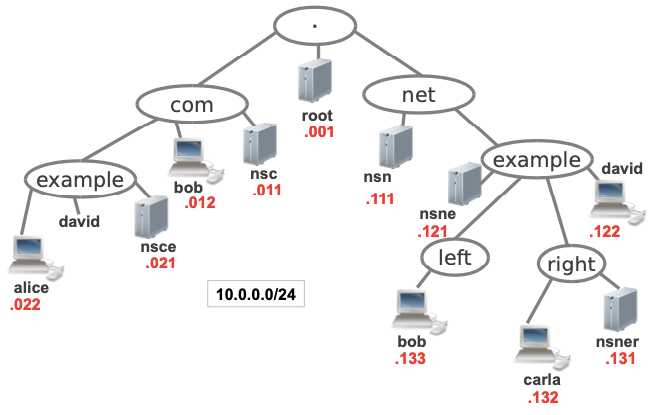
Obviously in the “real” Internet we have many different IP networks connected with routers.
Implementation with RRs
The DNS database in each server is implemented with Resource Records (RRs). RRs are text lines that define the configuration of the DNS tree nodes.
The general format of the RR is the following:
Owner [TTL] Class Type RDATA- Owner: RR owner, a name.
- TTL: the time that a RR may be cached by any resolver (optional).
- Class: Resource records belong to a class. Typically the class is IN (Internet)
- Type: The RR type.
- RDATA: Record information.
Resource Record “A”
The most common RR. It contains the IPv4 address associated with a name.
For example:
alice.example.com 30 IN A 10.0.0.22The A RR for the name alice.example.com with a TTL for caching of 30 seconds.
Resource Record “SOA”
The Source of Authority record is always the first record of a zone and it contains administrative information. Each zone must have a different SOA.
Each SOA contains the following RDATA:
- Origin: name of the zone’s primary server.
- Person: e-mail of the zone’s administrator.
- Serial: Integer (YYYY/MM/DD/XX) that must be increased after any modification of the zone data.
- Refresh: time between zone transfer requests by secondary servers (usually days).
- Retry: time between requests whenever a zone transfer fails (usually hours).
- Expire: time a secondary server keeps the data if the connection to the master fails (usually months).
- Negative cache: the time that an inexistent translation may be cached.
If we execute the following command dig @IP to know the RR of our router:
$ dig 192.168.1.1
; <<>> DiG 9.10.6 <<>> 192.168.1.1
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 58217
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;192.168.1.1. IN A
;; AUTHORITY SECTION:
. 3483 IN SOA a.root-servers.net. nstld.verisign-grs.com. 2021041600 1800 900 604800 86400
;; Query time: 147 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Fri Apr 16 16:52:20 CEST 2021
;; MSG SIZE rcvd: 115We can see either a type A RR and a SOA, with the following information:
serial: 2021041600
refresh: 1800
retry: 900
expire: 604800
negative cache: 86400
It says that the primary server of the zone is a.root-servers.net and the email of the admin of the zone is [email protected].
Resource Record “NS”
This RR stands for Name Server. NS RRs are used for delegation, they link a domain name with the name of an authoritative name server for that domain.
The configuration file of the zone will have as many NS records as domains being delegated in that specific zone.
It tells us which are the servers that serve the other zones that are delegated from the actual zone.
Glue Records
When we are in a certain zone, and we want to delegate to another one, we must indicate which is the name server of that zone with the NS record, as we’ve just seen. The problem is that the NS record does not contain any IP address, and if we are in root, and we want to reach nsc.com, and supposedly the one who knows the IP address of all devices from the zone .com is nsc.com, we will get in a loop.
Thats why we include another “A” record here, called glue record, to indicate the IP address of the server who serves that zone.
Notice that glue records are only necessary if the child zone has a name within the delegated domain, such as .com and nsc.com, then we would need to add a glue record to the .com zone configuration file.
Otherwise, we would only need a NS record (no extra “A” record) if the delegated zone is not related to the parent zone, because it will just send it to root, and it will later delegate it to the correct zone.
Resource Record “CNAME”
When there are several names that translate to the same IP address, we use the CNAME Resource Record. It creates an alias to a canonical name (CNAME).
This RR associates a name with another name of the DNS tree.
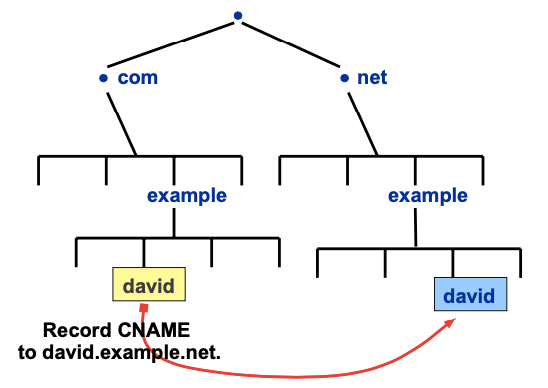
Resource Record “MX”
The MX (Mail eXchanger) records designate the mail servers for a given domain. We can add more than one MX record to each mail server for a certain email destination, just keep in mind that they will be contacted by priority order (low number first).
Configuration of DNS servers with BIND
In Linux, we use an implementation of the DNS called BIND (Berkeley Internet Name Domain (BIND), which is maintained by http://www.isc.org.
We will use bind to implement the configuration of our example DNS tree, which emulates a “mini” Internet. In Linux, you can start, stop or restart bind using the command $ /etc/init.d/bind9 stop/start/restart.
Each time you change the configuration of bind, you have to restart it so that changes take effect.
It is also worth knowing that BIND writes its logs by default in a Debian distribution in the file /var/log/daemon.log.
ROOT Servers
To send properly messages between different parts of the DNS tree, we must be able to go “up” the tree, and move to other zones that are not directly connected to the current zone.
That’s why any DNS server must have information about how to reach the root servers of the DNS tree. This informations is called root hints and, in our configuration, they are specified in the file /etc/bind/db.root.
We have configured it this way:
. IN NS ROOT-SERVER
ROOT-SERVER IN A 10.0.0.1Configuration of ROOT
The root server contains the configuration of the dot zone, which can generally be found at /etc/bind.
When the bind service wants to consult something, the first file it looks at is /etc/bind/named.conf. In root, the contents of this file are the following:
$ cat /etc/bind/named.conf
options {
directory "/var/cache/bind"; };zone "." {
type master ;
file "/etc/bind/db.root";
};zone "localhost" {
type master ;
file "/etc/bind/db.local";
};zone "0.0.10.in−addr.arpa" { type master ;
file "/etc/bind/db.10.0.0"; };We can see that for the “.” zone it tells us that the information to reach the “.” zone is inside /etc/bind/db.root
If we take a look at that file, we can see the following:
$ cat /etc/bind/db.root
TTL 60000 ; 16h40m default Time to Live of the
DNS records . IN SOA ROOT−SERVER. admin−mail .ROOT−SERVER.(
2006031201 ; serial
28800 ; refresh
14400 ; retry
3600000 ; expire
0 ; negative cache ttl
)
. IN NS ROOT-SERVER
ROOT-SERVER. IN A 10.0.0.1
com. IN NS nsc.com
nsc.com. IN A 10.0.0.11
net. IN NS nsn.net
nsn.net. IN A 10.0.0.111Notice that all names end with a dot “.”, that means that all those names are FQDN.
It also tells us which are the name servers that it delegates, and how to reach their zone.
Regarding our example, we can see how this file shows us the different NS and glue records for the three possible delegated zones (“.”, .com and .net).
Configuration of nsc.com
To take a look at the configuration of the server nsc.com, remember that we must look at the file /etc/bind/named.conf of that server.
We have the following in this file:
$ cat /etc/bind/named.conf
options {
directory "/ var / cache / bind ";
min−roots 1;
};zone "." {
type hint ;
file "/etc/bind/db.root"; };
....
// add entries for other zones below herezone "com" {
type master ;
file "/etc/bind/db.com";
};See how it indicates that we’ve got a hint to reach root at “/etc/bind/db.root”? Exactly how it is supposed to be!
Also notice how it says: “// add entries for other zones below here”, where we can add other child zones that can be connect to this server.
Configuration a zone
Let’s imagine now that we want to observe the configuration of one of the zones connected to the server nsc.com. The .com zone in this case.
To do so, we need to look inside the file /etc/bind/db.”ZONE”, in our case it would be /etc/bind/db.com.
This is what it says:
$ cat /etc/bind/db.com
TTL 60000 ; 16h40m default Time to Live of the DNS records
com. IN SOA nsc .com. admin−mail . nsc .com. (
2006031201 ; serial
28800 ; refresh
14400 ; retry
3600000 ; expire
0 ; negative cache ttl
)
com. IN NS nsc.com ; ns of .comnsc.com. IN A 10.0.0.11 ; leaf of .combob.com. 30 IN A 10.0.0.12 ; leaf of .comexample.com. IN NS nsce.example.com ; delegation of example.comnsce.example.com IN A 10.0.0.21 ; glue record of example.comThe file contains the TTL, and then the various RRs:
- SOA record with all it’s source of authority information
- NS record of .com zone, indicating who is the name server of .com
- Glue Record of nsc.com telling where nsc.com is
- A record for bob.com
- NS record of the example.com zone, indicating that nsce.example.com is the name server of example.com
- Glue record of nsce.example.com telling where nsce.example.com is found.
If we now take a look at the same file, but from the example.com zone, in the file /etc/bind/db.com.example:
$cat /etc/bind/db.com.example
$ORIGIN example.com.
$TTL 60000
@ IN SOA nsce admin−mail . nsce (
2006031201 ; serial
28 ; refresh
14 ; retry
3600000 ; expire
20 ; 20 secs of negative cache ttl
)@ IN NS nsce; unqualified namensce IN A 10.0.0.21david IN CNAME david.example.net.@ IN MX 10 mailserver1
@ IN MX 20 mailserver2.example.com.alice IN A 10.0.0.22mailserver1 IN A 10.0.0.25mailserver2 IN A 10.0.0.26;alice.example.com IN A 10.0.0.22Let’s take a closer look at this configuration file. The first thing that is different from the previous example is the $ORIGIN line. This is just to indicate that everywhere that a @ appears, it should be substituted by the ORIGIN value, in this case example.com.
Next on we find some RRs that we haven’t seen before, such as CNAME, which creates an alias from another point of the DNS tree, and links this two names to the same IP address, and also MX, which indicates who are the mail servers for example.com.
Finally take a look at the last line… It is commented, but if we uncomment (delete the semicolon) from that line, we are creating another A resource, and it renames the zone that is found at the IP address 10.0.0.22 to alice.example.com instead of alice.
DNS Queries & Responses
When a Linux device tries to find a translation for a name, the first thing it does is looking at the local translations file located at /etc/hosts.
If there is not any translation in this file, the client has to use the DNS service.
To do so, we need to know at least one name server. In Linux, the file /etc/resolv.conf is where the addresses of the name servers are stored.
The contents of the file are something like this:
nameserver 147.83.2.3
nameserver 147.83.2.10They are pointing to different name servers, to which the client will ask for DNS translations. In the resolv.conf you can set up to 3 name servers that will be contacted in order.
Obviously, the name servers to which you ask, must be configured to accept client queries.
Additional note: The name server is typically provided by your ISP or your organization.
Queries
In Linux we have 2 commands to perform DNS queries: host and dig.
Each query specifies the domain name, class and type of the queried RR. For example we can ask for klasea.es IN A.
There are 2 types of queries: iterative and recursive.
- In an iterative query, the queried name server returns the address of the next name server that you must consult to obtain the response.
- In a recursive query, the name server tries to find the final response, making several queries to different name servers if necessary. To use the recursive queries, we must activate the flag “recursion flag” on the request.
Be careful! Not all servers support recursion.
Responses
Name servers usually use a cache memory to improve the DNS performance. The time that a response is cached is configured by the original Source Administrator.
When we use cache, we have to possible types of responses:
- Authoritative: Authoritative name servers provide authoritative responses (not cached) because it is the original source.
- Non-authoritative: Non-authoritative name servers provide cached responses (with a valid TTL).
DNS Protocol
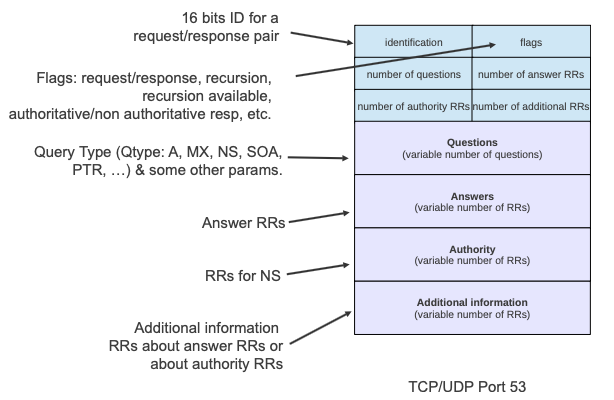
DNS servers use by default UDP port 53 , and DNS messages can have five parts:
- Header: here we can find if the message is a query or a reply, if recursion is desired or not, if the response is authoritative or not, etc.
- Questions: They are tuples with Name, Type and Class.
- Answers: Contain the registers that match the Name, Type and Class asked in the questions part.
- Authority: It typically contains NS records pointing to name servers closer to the target name in the hierarchy.
- Additional information: It contains additional records that the name server believes may be useful to the client. The most common use for this field is to supply A address records for the name servers listed in the Authority section.
Practical Name Resolutions
Querying an Authoritative Server
Normally clients will be asking queries to authoritative servers.
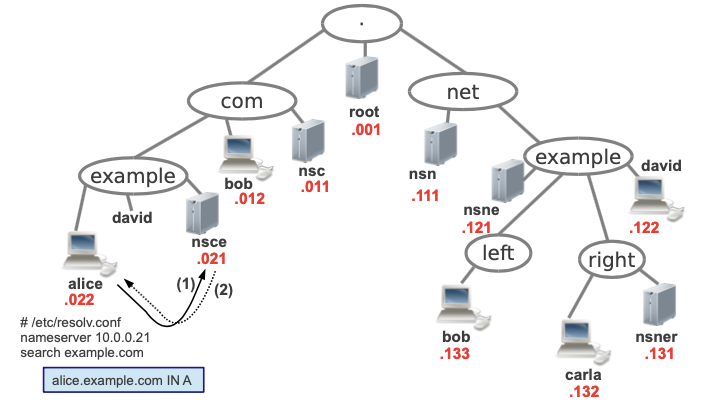
In our example let’s consider that Alice has nsce as her resolver (can be found in /etc/resolv.conf) and that she wants to know its own IP address.
To do so Alice will send a recursive query for the A register of alice.example.com to nsce.
Then nsce will send directly the response to Alice, as it already knows the answer.
The command Alice had to use to know her own IP address is: alice$ dig alice.example.com, and the response she obtains is the following:
; <<>> DiG 9.6-ESV-R4 <<>> alice.example.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 49052
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 1, ADDITIONAL: 1 ;; QUESTION SECTION:
;alice.example.com. IN A
;; ANSWER SECTION:
alice.example.com. 60000 IN A
;; AUTHORITY SECTION:
example.com. 60000 IN NS
;; ADDITIONAL SECTION:
nsce.example.com. 60000 IN A
;; Query time: 289 msec
;; SERVER: 10.0.0.21#53(10.0.0.21)
;; WHEN: Tue Mar 26 11:29:34 2013
;; MSG SIZE rcvd: 86Let’s examine the output, if we take a closer look at the flags it has we can see:
- aa: authoritative response
- rd: recursion desired
- ra: response available
If we now made a dig to a non-existent target:
alice$ dig alan.example.com
; <<>> DiG 9.6-ESV-R4 <<>> alan.example.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 39136
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION:
;alan.example.com. IN A
;; AUTHORITY SECTION:
example.com. 20 IN SOA nsce.example.com. ...As you can see the server returns a response with status NXDOMAIN, which means that a translation for that name was not found. It also returns a SOA RR, because it contains the negative TTL, which tells us how long we must store this information in the cache. In this case 20 seconds.
Non authoritative server
Until now we’ve seen how a server reacts when it is the authoritative server of the client who asked the query.
But what happens when a client wants to know the information of a host, who is not in the same zone, and so the previous server is not the authoritative server of the new zone?
Taking our example back, let’s imagine that from Alice, we want to find information about bob.com. The authoritative server of bob is nsc, in this case nsce does not know where it is.
We will test what happens using the dig command from alice, and capturing the traffic with wireshark (we will use the option Statistics -> Flow Graph).
$alice dig bob.com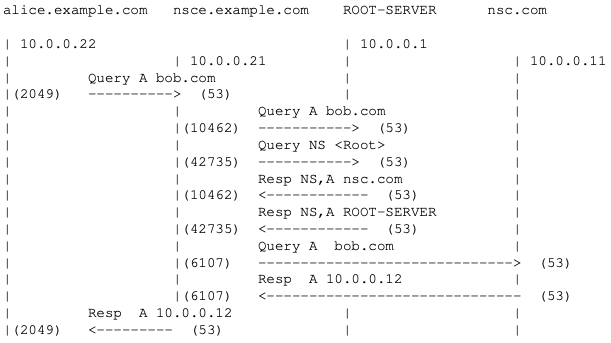
Let’s analyze what happens here.
- (1) First alice sends the query to its server, nsce, asking only for the A record.
- (2) nsce doesn’t know where to find bob.com, so it sends the query to it’s root server. In this case it asks for either the A record and the NS.
- (3) root responds with the NS and A records from either nsc and its own.
- (4) Now nsce knows that the NS of bob.com is nsc, and so forth it sends the query to nsc.com asking for the A record from bob.com.
- (5) nsc responds to nsce sending the A record of bob.com
- (6) nsce can tell now to alice where bob.com is located.
Take a look at the following image for a visual representation of the previous steps:
DNS caching
Name servers use caching to enhance the performance of the DNS system by storing the RRs obtained during the resolution process. These RRs are kept in cache until their TTL expires. A non authoritative server can use its cached RRs with valid TTL to answer its clients queries without contacting any other name servers.
Imagine that alice (or another user) asks again nsce for the A record of bob.com. As it still has it in its cache, then nsce can directly respond the query with its cached record.
Take into account that different RRs have different TTL, so maybe the A resource of bob.com is already expired, but the NS record that tells nsce that nsc is the name server of bob.com has not, and so nsce could ask directly to nsc for the A record of bob, without need to go to the root server.
Non Recursive Questions
If we try an iterative query with the dig command from alice to nsce, about bob.com, the input will be the following:
alice$ dig +noquestion +norecurse bob.com
; <<>> DiG 9.6-ESV-R4 <<>> +noquestion +norecurse bob.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30988
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; AUTHORITY SECTION:
. 0 IN NS ROOT-SERVER.As you can see, nsce returns the NS record of the ROOT-SERVER, which is the next server you have to contact to resolve bob.com.
If alice now asks root for bob.com:
alice$ dig +noquestion +norecurse @10.0.0.1 bob.com
; <<>> DiG 9.6-ESV-R4 <<>> +noquestion +norecurse @10.0.0.1 bob.com ; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 23767
;; flags: qr ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 1 ;; AUTHORITY SECTION:
com. 60000 IN NS nsc.com.
;; ADDITIONAL SECTION:
nsc.com. 60000 IN A 10.0.0.11We obtain the NS and A records of nsc which is the next server to resolve bob.com.
Great! Up to this point, we’ve been explaining all the basics to know how the DNS service resolves queries, and goes from one server to another.
The following sections are just extra information that imo are worth to mention, but in case you already found what you were looking for, or you just wanted to understand the DNS protocol, maybe you won’t need them, though I recommend you to take a look if you already reached this far!
Reverse Lookups
As you know, DNS allows to translate a FQDN to an IP address.
Reverse lookups allow exactly the opposite, translating IP addresses into FQDNs.
Some applications use the reverse translations as a measure of security, but the majority do not use them, as it is not compulsory.
The RR used for reverse lookups is called PTR (pointer), and as you may have guessed, it points to the corresponding FQDN.
If you want to ask for a reverse translation, you can use the dig command with the -x option: dig -x 147.83.2.135, and it will answer all the FQDNs that correspond to this IP address.
Other RRs
In this article I’ve explained the most common and compulsory RRs that the DNS uses. However, there are other ones that you may find
I’ve not went in depth with them because they are not as common as the ones we’ve seen, but just keep in mind that you may find additional RRs like:
- TXT: plaintext record containing optional information.
- HINFO: contains informative plain text about the server hardware and OS.
- LOC: contains geographical location of the server.
- AAAA: RR for IPv6 indicating the whole v6 address.
- SRV: allows specifying the location of the servers of a certain service.
Real Root Servers & Administration Authorities
In our example we’ve been using a “mini Internet” with only one root server. Obviously the real Internet does not have only one root server.
Initially there were 13 root-servers located in different countries.
Nowadays we still have 13 names for root servers which are specified in the form letter.root-servers.net, where letter ranges from A to M.
However this does not mean that we have only 13 physical servers. For reliability and performance, each name server is implemented using redundant computer equipment to be able to provide DNS service even if failure of hardware or software happens in one of the physical servers.
Finally, after talking about the different servers that we have around the world, it is worth mentioning the Internet Corporation for Assigned Names and Numbers (ICANN³), who is the responsible of managing different network parameters such as:
- Root and first level name servers
- Assignment of IP addresses
- Delegation of zones to RIRs (Regional Internet Registries)
Well, I guess this is a good starting point to understand the overall picture on how does DNS work. I hope you understood everything, and found it useful.
If you want to take a look at a practical exercise step by step on how to use DNS, using the same pictures and situations of this article, you can do it here!
For any doubts, hit me up at [email protected], I’ll be happy to share thoughts with you!
If you want to check my previous articles to understand some other Internet concepts feel free to do so!
Leave a clap if you enjoyed this post, you’ll support my work and help me keep myself motivated to write more! Knowledge is power!